Automate Data Transformations
Data-driven pipelines for machine learning healthcare automotive services unstructured data any data & language
Request a Demo





import cv2
import numpy as np
from matplotlib import pyplot as plt
import os
# edges.py reads an image and outputs transformed image
def make_edges(image):
img = cv2.imread(image)
tail = os.path.split(image)[1]
edges = cv2.Canny(img,100,200)
plt.imsave(os.path.join("/pfs/out", os.path.splitext(tail)[0]+'.png?as=webp'), edges, cmap = 'gray')
# walk images directory and call make_edges on every file found
for dirpath, dirs, files in os.walk("/pfs/images"):
for file in files:
make_edges(os.path.join(dirpath, file))

Automatic and intelligent versioning of even the largest data sets of unstructured and structured data.
Git-like structure enables effective team collaboration. Full versioning for metadata including all analysis, parameters, artifacts, models, and intermediate results.
Automatically produces an immutable record for all activities and assets.
Pachyderm is used across a variety of industries and use cases. Pachyderm provides a powerful solution to optimize data processing, MLOps, and ML Lifecycles.
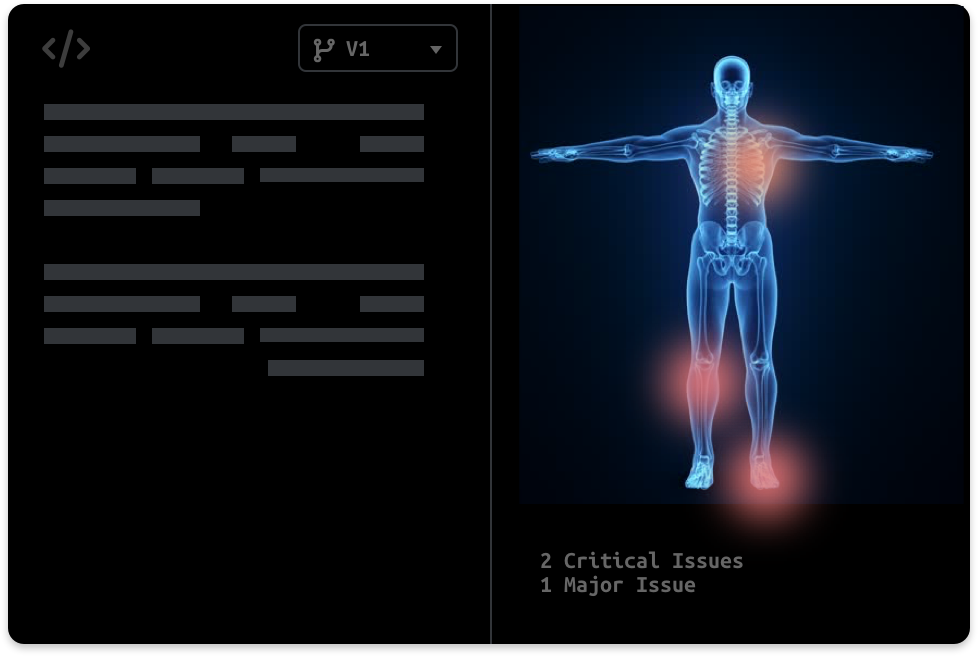
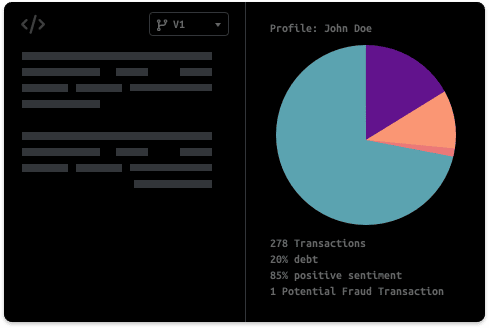



We understand that you support Data Scientists, MLOps and other infrastructure teams. They will love Pachyderm too!
Data Science Support: Let Pachyderm be the single source of truth for your data. Use familiar Jupyter notebooks to experiment and iterate with your data collaboratively, while always remaining in sync.
MLOps Support: We work with the standard Kubernetes tools, integrate into existing systems and run across all cloud and on-premises providers.
Pachyderm is container-native, running with standard containerized tooling and allows engineers complete autonomy to use whatever languages or libraries are best for the job.
Pachyderm is data-agnostic, supporting both unstructured data such as videos and images as well as tabular data from data warehouses.
Explore the Docs
import cv2
import numpy as np
from matplotlib import pyplot as plt
import os
# edges.py reads an image and outputs transformed image
def make_edges(image):
img = cv2.imread(image)
tail = os.path.split(image)[1]
edges = cv2.Canny(img,100,200)
plt.imsave(os.path.join("/pfs/out", os.path.splitext(tail)[0]+'.png'), edges, cmap = 'gray')
# walk images and call make_edges on every file found
for dirpath, dirs, files in os.walk("/pfs/images"):
for file in files:
make_edges(os.path.join(dirpath, file))
var cv2 = require('cv2');
var np = require('numpy');
from matplotlib var plt = require('pyplot');
var os = require('os');
// make_edges reads an image from /pfs/images and outputs the result of running
// edge detection on that image to /pfs/out. Note that /pfs/images and
// /pfs/out are special directories that Pachyderm injects into the container.
function make_edges(image) {
img = cv2.imread(image);
tail = os.path.split(image)[1];
edges = cv2.Canny(img,100,200);
plt.imsave(os.path.join('/pfs/out', os.path.splitext(tail)[0]+'.png'), edges, cmap = 'gray');
}
// walk /pfs/images and call make_edges on every file found
for (dirpath, dirs, files in os.walk('/pfs/images')) {
for (file in files) {
make_edges(os.path.join(dirpath, file));
}
}
package it.polito.elite.teaching.cv;
/**
* @author luigi.derussis@polito.it Luigi De Russis
*/
public class HelloCV
{
public static void main(String[] args)
{
// load the OpenCV native library
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
// create and print on screen a 3x3 identity matrix
System.out.println("Create a 3x3 identity matrix...");
Mat mat = Mat.eye(3, 3, CvType.CV_8UC1);
System.out.println("mat = " + mat.dump());
// prepare to convert a RGB image in gray scale
String location = "resources/Poli.jpg";
System.out.print("Convert the image at " + location + " in gray scale... ");
// get the jpeg image from the internal resource folder
Mat image = Imgcodecs.imread(location);
// convert the image in gray scale
Imgproc.cvtColor(image, image, Imgproc.COLOR_BGR2GRAY);
// write the new image on disk
Imgcodecs.imwrite("resources/Poli-gray.jpg", image);
System.out.println("Done!");
}
}
import scala.io.Source
import java.io.PrintWriter
object RemoveNan {
def main(args: Array[String]): Unit = {
// Read the csv file and store it as a list of strings
val lines = Source.fromFile("/pfs/input_repo/input.csv").getLines.toList
// Filter out rows containing Nan values
val cleanRows = lines.filter(line => !line.contains("Nan"))
// Write the filtered rows to a new csv file
val writer = new PrintWriter("/pfs/out/output.csv")
cleanRows.foreach(line => writer.write(line + "\n"))
writer.close()
}
}



Pachyderm is data-agnostic, supporting both unstructured data such as videos and images as well as tabular data from data warehouses.
Pachyderm is container-native, running with standard containerized tooling and allows engineers complete autonomy to use whatever languages or libraries are best for the job.
Pipelines are intelligently triggered by detecting changes to data, which is all automatically version controlled by the platform.

Learn how companies around the world are using Pachyderm to automate complex pipelines at scale.
Request a DemoLearn how companies around the world are using Pachyderm to automate complex pipelines at scale.
Pachyderm helps us convert our existing data science pipelines from manually managed scripts to scalable, repeatable end-to-end workflows; enabling us to focus more on developing transformative technology to drive agriculture forward instead of wrangling infrastructure.
View Case Study