
Pachyderm is cost-effective at scale, enabling data engineering teams to automate complex pipelines with sophisticated data transformations.
Leverage your infrastructure investments and run on your existing cloud or on-premises infrastructure.
Run any data type, size, or scale of data in both batch or real-time pipelines.
Support effective team collaboration through git-like structure of commits.

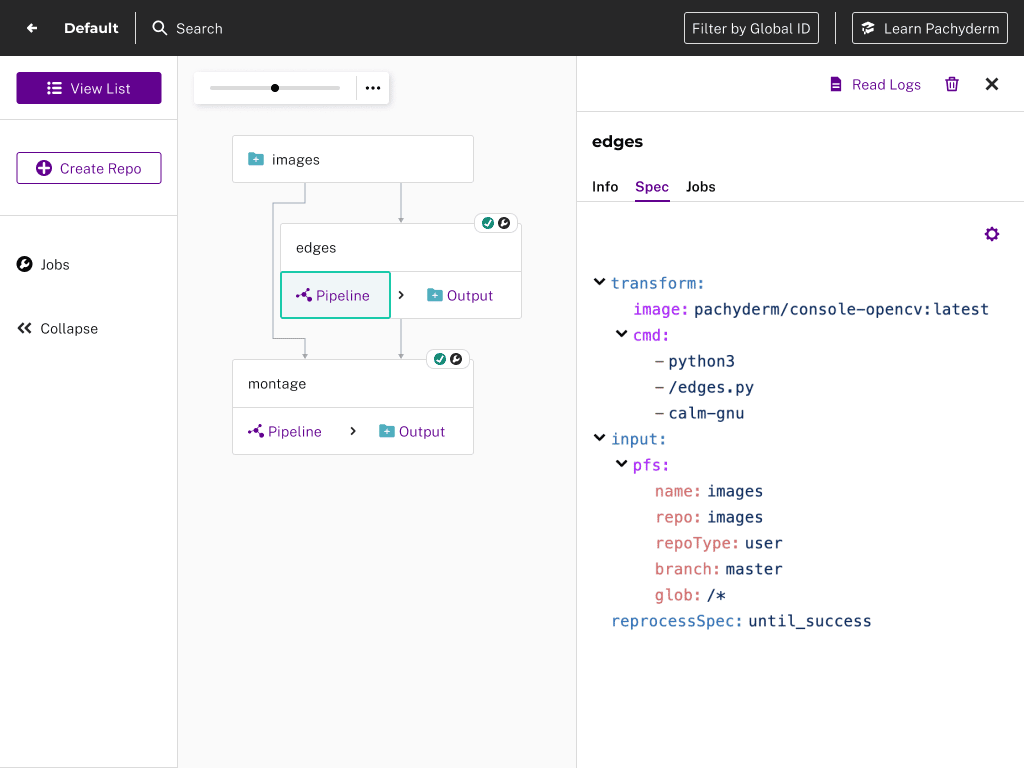
Console is a complete web UI for visualizing running pipelines and exploring your data.
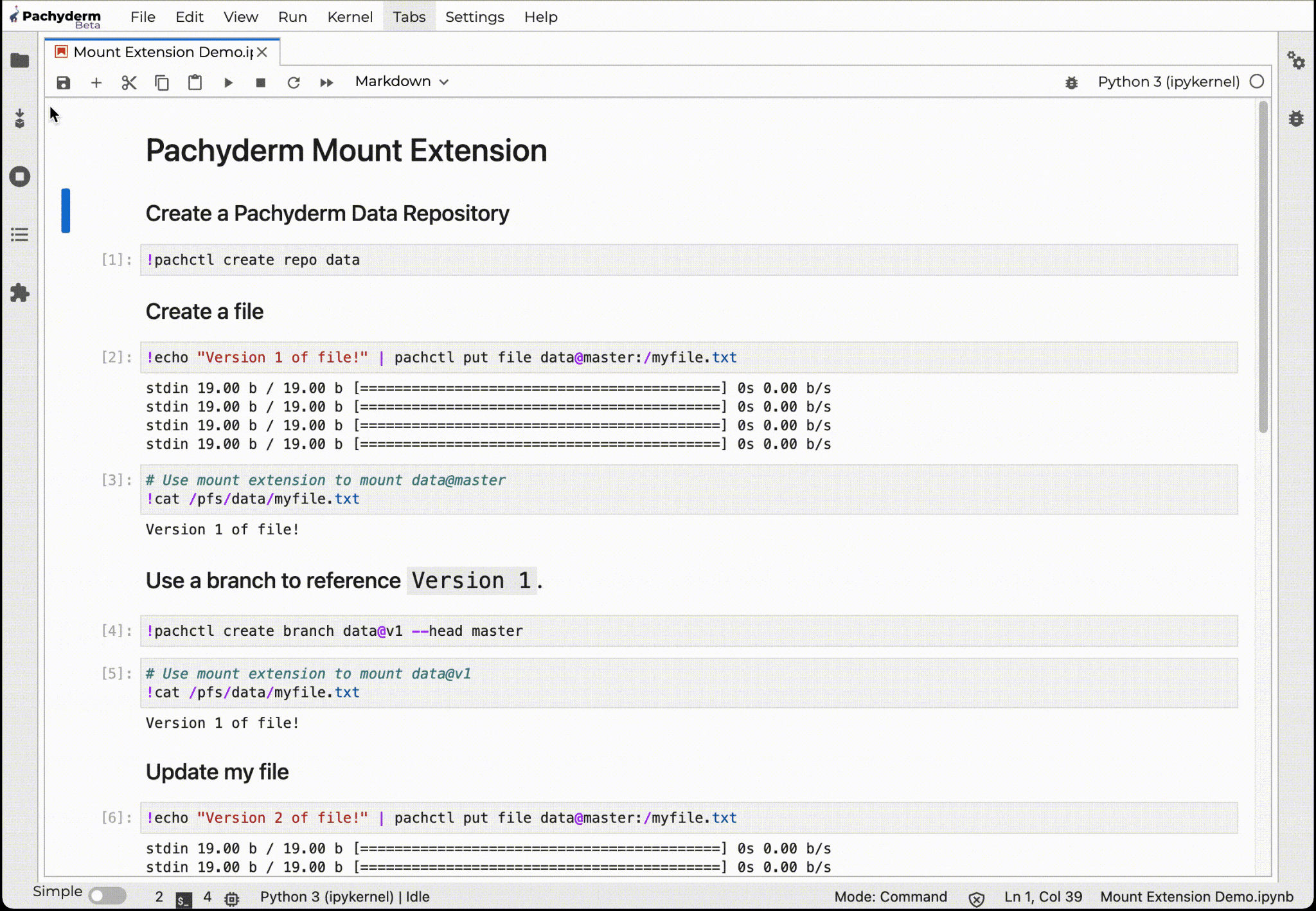
JupyterLab mount extension that selectively maps the contents of data repositories right into your Jupyter environment.
Robust tools for deploying and administering Pachyderm at scale across different teams in your organization.
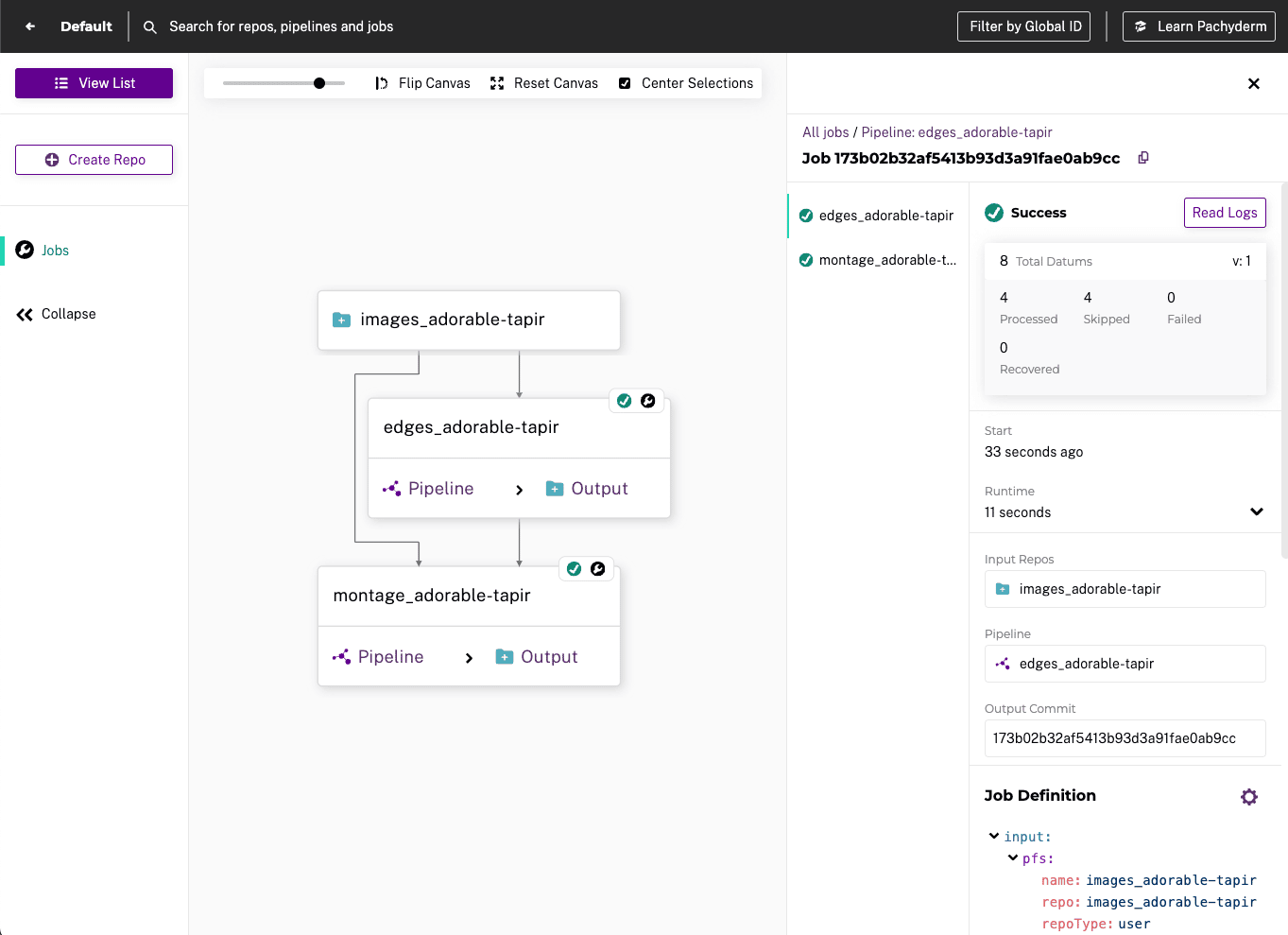
Watch a short 5-minute demo which outlines the product in action

Learn how companies around the world are using Pachyderm to automate complex pipelines at scale.
Request a Demo