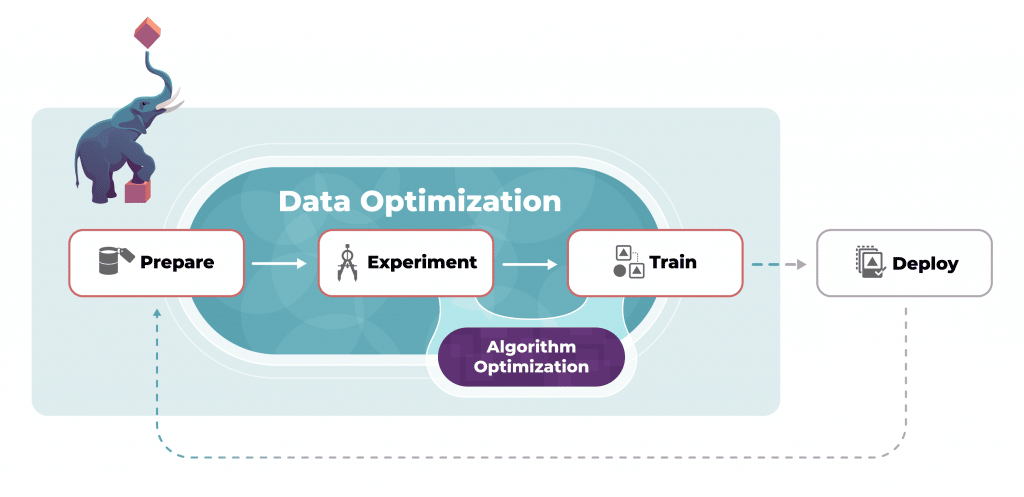
Transform your Data Pipeline
Scale and enable data engineering teams to automate complex pipelines with sophisticated data transformations.
Enterprise Edition
For organizations and teams that require advanced features and unlimited potential.
- Unlimited Data Driven Pipelines
- Unlimited Parallel Processing
- Role Based Access Controls (RBAC)
- Pluggable Auth - Login with your IdP
- Enterprise Support
Community Edition
Free Download